Не секрет, что иногда выделение памяти требует отдельных решений.
Например — когда память выделяется и освобождается стремительным домкратом потоком, в параллельных задачах.
В результате стандартный консервативный аллокатор выстраивает все
запросы в очередь на pthread_mutex / critical section. И наш
многоядерный процессор медленно и печально едет на первой передаче.
И что с этим делать? Познакомимся поближе с деталями реализации метода
Scalable Lock-Free Dynamic Memory Allocation. Maged M. Michael. IBM
Thomas J. Watson Research Center.
Самый простой код что я сумел найти — написан под LGPL камрадами Scott Schneider и Christos Antonopoulos. Его и рассмотрим.
Начнем издалека

Итак — как нам избавиться от ненужных локов?
Ответ лежит на поверхности — надо выделять память в lock-free списках. Хорошая идея — но как строятся такие списки?
На помощь нам спешат атомарные операции. Те самые, которые
InterlockedCompareExchange. Но постойте — максимум на что мы можем
рассчитывать это long long, он же __int64. И что делать? А вот что —
определим свой собственный указатель с тегом.
Ограничив размер адреса в 46 бит, и мы можем в 64бит целое спрятать нужные нам дополнения, а они — понадобятся далее.
#pragma pack(1)
typedef struct {
volatile unsigned __int64 top:46, ocount:18;
} top_aba_t;
Кстати, с учетом выравнивания по 8 / 16 байт — мы можем получить не 2
в 46 степени, а несколько больше. Стандартный прием — выданный адрес не
может быть нечетным и более того — должен быть выровнен для плавающей
точки.
И еще момент — код становится очень длинным. То есть стандартная портянка
desc->Next = queue_head;
queue_head = desc;
превращается вот в такие макароны
descriptor_queue old_queue, new_queue;
do {
old_queue = queue_head;
desc->Next = (descriptor*)old_queue.DescAvail;
new_queue.DescAvail = (unsigned __int64)desc;
new_queue.tag = old_queue.tag + 1;
} while (!compare_and_swap64k(queue_head, old_queue, new_queue));
что сильно удлиняет код и делает его менее читабельным. Поэтому очевидные вещи убраны под спойлеры.
Lock-free FIFO queue

Раз у нас теперь есть собственный указатель, можем заняться списком.
struct queue_elem_t {
char *_dummy;
volatile queue_elem_t *next;
};
И в нашем случае — не забыть про выравнивание, например так
typedef struct {
unsigned __int64 _pad0[8];
top_aba_t both;
unsigned __int64 _pad1[8];
} lf_fifo_queue_t;
Оборачиваем работу с атомарными функциями

Теперь определим парочку абстракций, чтобы наш код мог быть переносим (для Win32 например это реализуется вот так):
Обертка над атомами для Win32
и добавим еще один метод, просто чтобы не отвлекаться на кастинг параметров к __int64 и передаче их по указателям.
#define compare_and_swap64k(a,b,c) \
compare_and_swap64((volatile unsigned __int64*)&(a), \
*((unsigned __int64*)&(b)), \
*((unsigned __int64*)&(c)))
И вот мы уже готовы реализовать базовые функции (добавить и удалить).
Определяем базовые функции работы со списком

static inline int lf_fifo_enqueue(lf_fifo_queue_t *queue, void *element) {
top_aba_t old_top;
top_aba_t new_top;
for(;;) {
old_top.ocount = queue->both.ocount;
old_top.top = queue->both.top;
((queue_elem_t *)element)->next = (queue_elem_t *)old_top.top;
new_top.top = (unsigned __int64)element;
new_top.ocount += 1;
if (compare_and_swap64k(queue->both, old_top, new_top))
return 0;
}
}
На что тут надо обратить внимание — обычная операция по добавлению
обернута циклом, выход из которого — мы успешно записали новое значение
поверх старого, и при этом старое кто-то еще не поменял. Ну а если
поменял — то повторяем все заново. И еще момент — в наш ocount
записываем номер попытки, с которой нам это удалось. Пустячок, а каждая
попытка выдает уникальное 64бит целое.
Именно на таком простом шаманстве и строятся lock-free структуры данных.
Аналогичным образом реализуется снятие с вершины нашего FIFO списка:
Аналогично lf_fifo_dequeue
Тут мы видим ровно то же самое — в цикле пробуем снять, если есть что и
мы снимаем так что старое значение все еще правильное — то отлично, а
нет — пробуем еще.
И конечно же инициализация такого элемента списка банальна — вот она:
lf_fifo_queue_init
Собственно идея аллокатора

Перейдем теперь непосредственно к аллокатору. Аллокатор должен быть
быстрым — поэтому разделим память на классы. Большой (напрямую берем у
системы), и маленький, побитый на много-много маленьких подклассов
размером от 8 байт до 2 килобайт.
Такой ход конем позволит нам решить две задачи. Первая — маленькие
кусочки будут выделяться супербыстро, и за счет того что они разделены в
таблицу — не будут лежать в одном огромном списке. А большие куски
памяти не будут мешаться под ногами и приводить к проблемам с
фрагментацией. Более того — поскольку в каждом подклассе у нас все блоки
одного размера, работа с ними очень упрощается.
И еще момент! Выделение маленьких кусочков привяжем к нитям (а
освобождение — нет). Таким образом мы убьем двух зайцев сразу —
упростится контроль за выделением, и острова памяти выделенные для треда
локально — не будут перемешиваться лишний раз.
Получим нечто вот такое:
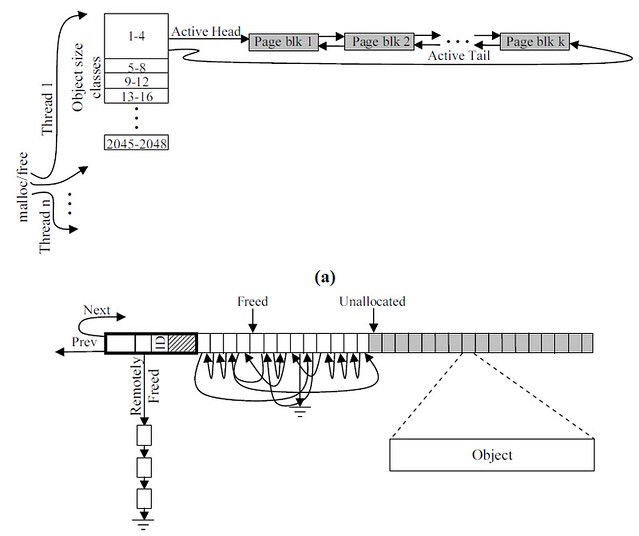
А вот так данные будут раскладываться по суперблоку:
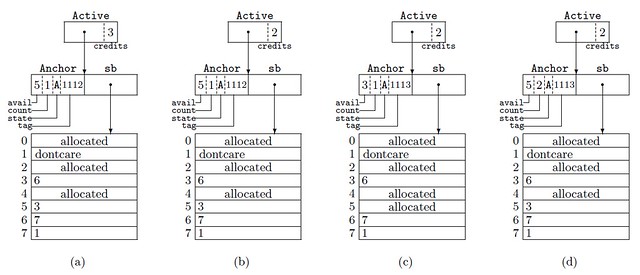
На картинке мы видим 4 случая
- Активный суперблок содержит 5 элементов организованных в список, 4 из них доступны для использования.
- А теперь мы зарезервировали следующий элемент (см credits)
- И в результате выдали блок номер 5
- А потом его вернули обратно (но попал он в partial list)
Опишем хип и дескриптор блока

Помолясь богине Техно, приступим.
Определим парочку констант
Балнальщина а-ля GRANULARITY и PAGE_SIZE
И займемся креативом, определим нужные типы данных. Итак, у нас будет
много хипов — каждый в своем классе, да привязанных к текущему треду. В
суперблоке будет два указателя — активный список и перераспределенный.
Вы спросите — а что это такое и почему так сложно?
Первое, оно же главное — выделять список поэлементно банально невыгодно.
То есть — классический однонаправленный список при миллионах элементов
превращается в ад и израиль. На каждый элемент списка надо выделить 8 /
16 байт, чтобы хранить два несчастных указателя на сами данные и на
следующий элемент списка.
Выгодно ли это? Очевидно что — нет! И как следует поступить? Правильно, а
давайте мы сгруппируем наши описатели списка в группы (stripe) по 500
(к примеру) элементов. И получим список не элементов, но — групп.
Экономично, практично, работать с элементами можно как и в классическом
варианте. Весь вопрос только в нестандартном выделении памяти.
Более того, все Next в пределах блока просто указывают на соседний
элемент массива, и мы можем их явно проинициализировать сразу при
выделении страйпа. По факту, последний Next в страйпе будет указывать на
следующий страйп, но с точки зрения работы со списками — ничего не
меняется.
Легко догадаться, что списки memory block descriptors строятся именно так.
И еще — Active и есть наш активный страйп с заранее выделенными
кусочками памяти по эн байт, в котором и ведем выдачу памяти по принципу
FIFO. Если есть место в страйпе — берем оттуда. Если нет — ищем уже в
классическом списке Partial. Если нет ни там ни там — отлично, выделяем
новый страйп.
Второе, такая «полосатость» ведет к некоторому перерасходу памяти, т. к.
мы можем выделить страйп под 8 байтные кусочки памяти в виде массива в
64К, а запрошено будет пара кусочков всего. И еще, активные страйпы для
каждой нити свои, что еще больше усугубит проблему.
Однако, если у нас действительно идет активная работа с памятью, это даст хороший выигрыш по скорости.
Вот сам хип
struct Procheap {
volatile active Active;
volatile descriptor* Partial;
sizeclass* sc;
};
А вот что ему надо:
Что это за Active / Partial такие
и собственно дескриптор — описатель нашего фрагмента.
struct Descriptor {
struct queue_elem_t lf_fifo_queue_padding;
volatile anchor Anchor;
descriptor* Next;
void* sb;
procheap* heap;
unsigned int sz;
unsigned int maxcount;
};
Как видно — ничего сверхъестественного. Описание хипа и суперблока нам
нужны в дескрипторе, т. к. выделять память можно в одном треде, а
освобождать — в другом.
Приступим к реализации

Сначала нам надо определить наши локальные переменные — хипы, размеры и прочее. Вот примерно так:
Как же без глобальных переменных
Тут мы видим все то, что рассматривали в предыдущем разделе:
__declspec(thread) procheap* heaps[2048 / GRANULARITY];
static volatile descriptor_queue queue_head;
Это и есть наши хипы per thread. И — список всех дескрипторов per-process.
Malloc — как это работает
Рассмотрим собственно процесс выделения памяти подробнее. Легко увидеть несколько особенностей, а именно:
- Если запрошенный размер не имеет нашего хипа для малых размеров — просто запрашиваем у системы
- Выделяем память по очереди — сначала из активного списка, затем из
списка фрагментов, и наконец — пробуем запросить у системы новый кусок.
- У нас всегда есть память в системе, а если нет — надо только подождать в цикле
Вот такое решение.
void* my_malloc(size_t sz) {
procheap *heap;
void* addr;
heap = find_heap(sz);
if (!heap)
return alloc_large_block(sz);
for(;;) {
addr = MallocFromActive(heap);
if (addr) return addr;
addr = MallocFromPartial(heap);
if (addr) return addr;
addr = MallocFromNewSB(heap);
if (addr) return addr;
}
}
Углубимся в тему, рассмотрим каждую часть в отдельности. Начнем с начала — с добавления нового куска из системы.
MallocFromNewSB
Никаких чудес — всего лишь создание суперблока, дескриптора, и
инициализация пустого списка. И добавление в список активных нового
блока. Тут прошу обратить внимание на такой факт, что нет цикла с
присваиванием. Если не удалось — значит не удалось. Почему так? Потому
что функция и так вызывается из цикла, а если не удалось вставить в
список — то это значит что вставил кто-то другой и надо проводить
выделение памяти сначала.
Перейдем теперь к выделению блока из списка активных — ведь мы уже научились выделять суперблок и прочее.
MallocFromActive
Собствено алгоритм прост, лишь слегка путает нас громоздкая форма
записи. На самом же деле — если есть что брать, то берем новый кусок из
суперблока, и отмечаем сей факт. Попутно проверяем — а не забрали ли мы
последний кусочек, и если да — отмечаем и это.
Есть тут роано одна тонкость, а именно — если вдруг выяснилось, что мы
взяли последний кусочек из суперблока, то вслед за нами следующий запрос
приведет к добавлению нового суперблока взамен уже использованного. И
как только мы это обнаружили — нам негде записать факт того что блок
выделен. Поэтому мы заносим только что выделенный кусочек в partial
list.
UpdateActive
Настала пора рассмотреть работу с дескрипторами, прежде чем мы перейдем к заключительной части этого эссе.
Memory Block Descriptors

Для начала, научимся дескриптор создавать. Но где? Вообще-то, если кто
забыл — мы как раз пишем выделение памяти. Очевидным и красивым решением
было бы использование тех же механизмов, что и для generic allocation,
но увы — это будет всем известный анекдот pkunzip.zip. Поэтому принцип
тот же — выделяем большой блок содержащий массив дескрипторов, и как
только массив переполняется — создаем новвый и объединяем его с
предыдущим в список.
DescAlloc
Ну а теперь дело за не менее мощным колдунством — надо еще и научиться
дескриптор обратно возвращать. Однако, возвращать мы будем в том же FIFO
— потому что возвращать нам понадобится только если мы его взяли по
ошибке, а этот факт обнаруживается сразу. Так что дело оказывается
гораздо проще
DescRetire
Helpers

Приведем также вспомогательные функции по инициализации списков и т. д.
Функции настолько самоочевидны, что их даже описывать как-то смысла нет.
organize_list
organize_desc_list
mask_credits
Суперблок просто запрашиваем у системы:
static void* AllocNewSB(size_t size, unsigned long alignement) {
return VirtualAlloc(NULL, size, MEM_COMMIT, PAGE_READWRITE);
}
Точно так же получаем большие блоки, запросив чуть больше под заголовок блока:
alloc_large_block
А это — поиск в нашей таблице хипа адаптированного под нужный размер (bkb ноль если размер слишком велик):
find_heap
А вот обертки для списков. Они добавлены исключительно для наглядности —
кода с макаронами вокруг атомиков у нас более чем достаточно, чтобы в
одну функцию yt складывать по надцать циклов вокруг compare and swap
ListGetPartial
ListPutPartial
Удаление строится банальнейше — перестройкой списка во временный и обратно:
ListRemoveEmptyDesc
И несколько оберток вокруг partial lists
RemoveEmptyDesc
HeapGetPartial
HeapPutPartial
Последний рывок — и выделять / освобождать готов!

И наконец мы готовы реализовать выделение памяти не в страйпе, все возможности для этого у нас уже есть.
Алгоритм прост — находим наш список, резервируем в нем место (попутно освобождая пустые блоки), и возвращаем его клиенту.
MallocFromPartial
Теперь рассмотрим как вернуть нам память обратно в список. В общем —
классический алгоритм: по переданному нам указателю восстанавливаем
дескриптор, и по якорю запомненному в дескрипторе — попадаем в нужное
нам место суперблока и отмечаем нужный кусочек как свободный, а кто до
сих дочитал тому пиво. И конечно же пара проверок — не надо ли нам
освободить весь суперблок, а то в нем он последний неосвобожденный.
void my_free(void* ptr) {
descriptor* desc;
void* sb;
anchor oldanchor, newanchor;
procheap* heap = NULL;
if (!ptr) return;
ptr = (void*)((char*)ptr - HEADER_SIZE);
if (*((char*)ptr) == (char)LARGE) {
munmap(ptr, *((unsigned long *)((char*)ptr + TYPE_SIZE)));
return;
}
desc = *((descriptor**)((char*)ptr + TYPE_SIZE));
sb = desc->sb;
do {
newanchor = oldanchor = desc->Anchor;
*((unsigned long*)ptr) = oldanchor.avail;
newanchor.avail = ((char*)ptr - (char*)sb) / desc->sz;
if (oldanchor.state == FULL) newanchor.state = PARTIAL;
if (oldanchor.count == desc->maxcount - 1) {
heap = desc->heap;
newanchor.state = EMPTY;
}
else
++newanchor.count;
} while (!compare_and_swap64k(desc->Anchor, oldanchor, newanchor));
if (newanchor.state == EMPTY) {
munmap(sb, heap->sc->sbsize);
RemoveEmptyDesc(heap, desc);
}
else if (oldanchor.state == FULL)
HeapPutPartial(desc);
}
На что надо обратить внимание — освобожденные кусочки попадают в partial
list, и было бы неплохо добавить проверку — а не попадает ли наш
кусочек на вершину Active страйпа, это бы неплохо повысило эффективность
вырожденного случая «выделяем и освобождаем в цикле». Но это уже в
качестве домашнего задания.
Выводы

В данной крайне занудной и длинной работе мы рассмотрели как можно
построить свой аллокатор на lock-free FIFO lists, узнали что это вообще
такое, и освоили немало трюков по работе с атомиками. Надеюсь, умение
группировать списки в страйпы поможет не только в деле написания своего
менеджера памяти.
Дополнительные материалы
- Scalable Lock-Free Dynamic Memory Allocation
- Hoard memory allocator
- Scalable Locality-ConsciousMultithreaded Memory Allocation
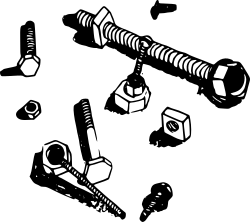
И в заключение, вот парочка иллюстраций из [3] о скорости работы разных аллокаторов (картинка кликабельна).
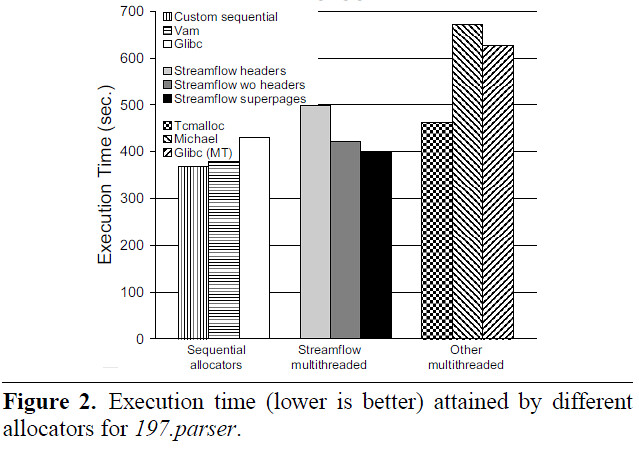
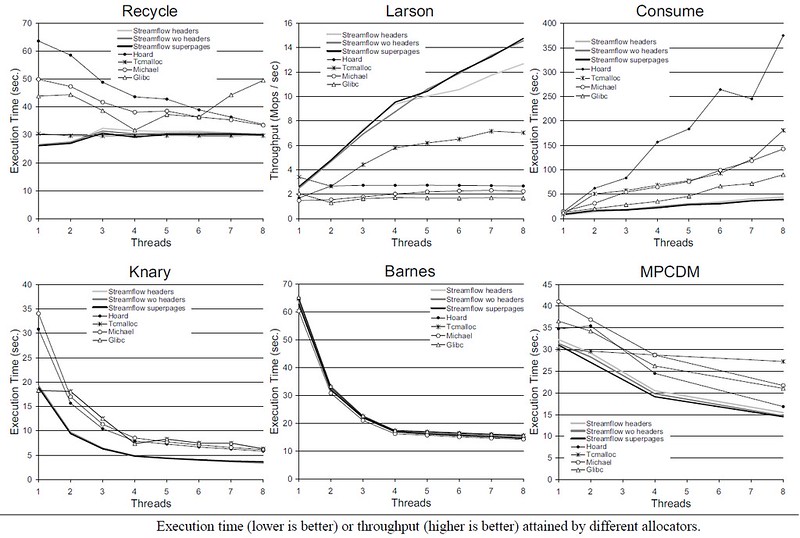
Как видно, несмотря на явную простоту алгоритма, работает он на уровне
лучших образцов, многие из которых появились сильно позже.
Update: спасибо SkidanovAlex за развернутое пояснение:
Из статьи не понятно, зачем нужен ocount. Это реализация так назвыемых
tagged pointer. Идея в том, что если бы его не было, то возможен был бы
такой сценарий (называется проблемой ABA — поэтому и структура в статье называется top_aba_t):
Пусть операция pop выглядит примерно так:
do {
long snapshot = stack->head;
long next = snapshot->next;
} while (!cas(&stack->head, next, snapshot));
В принципе код deque в статье делает именно это, но с ocount. Теперь
рассмотрим такой сценарий: на вершине стека лежит элемент А, за ним
элемент B (стек выглядит как A -> B). Мы запомнили snapshot = A, next
= B.
В этот момент другой поток убрал элемент A, затем вставил элемент C, и вставил обратно А. Теперь стек выглядит как:
A -> C -> B.
Операция pop просыпается, и ее CAS срабатывает (stack->head ==
snapshot, они оба равны A), и заменяет stack->head на B. Элемент C
теряется.
С ocount такого не произойдет, потому что свежевставленный A будет иметь другой ocount, и CAS провалится.
Но ocount спасает конечно только на практике. В теории после того как мы
запомнили snapshot и next другой поток может удалить A 2^18 раз, пока
ocount не примет такое же значение как было, и ABA проблема опять
произойдет.
На современном железе конечно никто не отводит под указатель 48 бит.
Вместо этого используется две 64-битных переменных, идущих подряд,
первая под указатель, вторая под ocount (теоретический сценарий с
вставкой элемента А много раз становится еще более теоретическим), и
используется double cas.
Материал взят -> ПАМЯТЬ
|